You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
RAID 101
- Thread starter Praetor
- Start date
- Status
- Not open for further replies.
Section 1 -- Definitions
RAID or redundant array of inexpensive drives, is a harddrive configuration similar to a jbod (just-a bunch of drives) however it expands on this by adding performance and/or reliability 'enhancements' (the specific enhancements depend on the type, or level or RAID in question)
Striping refers to the process of splitting data across multiple drives. The advantage to doing this is that access times for the overal data is reduced because consequtive operations (whether it be reading or writing) will occur off alternating/different drives. A quick example of this:
Task -- access five data "units". All drives involved will be assumed to have an access time of 10ms.
Scenario 1 -- all five data units are stored on a single drive. in this case, accessing the five data units requires 50ms.
Spanning. Windows for instance, has a 26 drive limit (one drive for each letter of the alphabet) ... Now suppose you have, for whatever reason, a requirement for 30 harddrives. This can be done via spanning. What this means is that, at a hardware level, multiple harddrives are grouped/clumped together as a single logical drive (so as far as the OS is concerned, there arent more than 26 drives however the user still has the available capacity of the 30 drives).
Parity. This generically refers to some scheme for creating recovery data. In the event of a data failure, the parity information can be used in conjunction with existing data to reconstruct the 'lost' data.
Mirroring. Drive/data mirroring is just that: data stored on drive a is duplicated on drive b; the difference between mirrorign and a parity configuration is that, in the event of a drive failure, a mirrored setup does not require any "reconstruction" since any data stored on a given drive is also stored on the other drive.
Fault tolerance. Generally expressed in degrees/levels, fault tolerance, in the context of RAID, refers to the number of simultaneous critical drive failures a configuration can sustain without loss of user data. Take mirroring for instance, since any data on drivea is stored on driveb, either drive can fail without loss of data (thus meaning the fault tolerance is 1-drive); should both drives fail, the user will lose their data
Controller. Raid doesn't just "happen" by plugging harddrives into a standard controller however, they require special drive controllers which provide the RAID functionality (naturally this does not refer to software-RAID). The type of RAID available depends on the controller.
Software-RAID. At the OS-level, the OS can 'reroute it's io operations' to simulate a hardwareRAID; such implementations are called software-RAID. The advantage here is that there is no longer a requirement for fancy (and potentially expensive) RAID controllers; the downside is that (a) you cannot 'simulate' all possible RAID levels and (b) performance of a software-RAID will never be able to match a hardware implenmentation.
Sequential vs Random Like the word suggests, sequential refers to accessing data such that the data blocks are arranged sequentially (with repsect to the physical location on the plates) on the disk. Random access refers to non-sequential access.
Hotswap Hotswapping refers to [the ability to] remove a harddrive from a system while the system is still powered up. If you have to power-down before swapping out a HDD then your drive does not support hot-swapping
Matrix/nForce RAID
Intel Matrix RAID -- http://www.intel.com/design/chipsets/matrixstorage_sb.htm
nVidia RAID -- http://www.nvidia.com/object/feature_raid.html
RAID or redundant array of inexpensive drives, is a harddrive configuration similar to a jbod (just-a bunch of drives) however it expands on this by adding performance and/or reliability 'enhancements' (the specific enhancements depend on the type, or level or RAID in question)
Striping refers to the process of splitting data across multiple drives. The advantage to doing this is that access times for the overal data is reduced because consequtive operations (whether it be reading or writing) will occur off alternating/different drives. A quick example of this:
Task -- access five data "units". All drives involved will be assumed to have an access time of 10ms.
Scenario 1 -- all five data units are stored on a single drive. in this case, accessing the five data units requires 50ms.
Chunk 1 is found off drive a - 10ms
Chunk 2 is found off drive a - 10ms
Chunk 3 is found off drive a - 10ms
Chunk 4 is found off drive a - 10ms
Chunk 5 is found off drive a - 10ms
Scenario 2 -- data is striped across two drives. in this scenario, while data chunk x is being located, data chunk x+1 is being simultaneously seeked. For simplicity sake, suppose the overlap time is 5ms (50% of the original seek time). Thus, in this highly simplified example, the total access time is 30ms. Chunk 1 is found off drive a - 10ms
Chunk 2 is found off drive b - 5ms
Chunk 3 is found off drive b - 5ms
Chunk 4 is found off drive b - 5ms
Chunk 5 is found off drive b - 5ms
Scenario 3 - data is striped across three drives -- an extension of the second example except now, while data chunk x is being accessed (requiring 10ms), data chunk x+1 is beeing seeked (with an overlap of 5ms) and data chunk x+2 is being seeked (with an overlap of 2. 5ms, taken as half of the previous ... Again, for simplicity sake). Your net seek time will be 22. 5msChunk 1 is found off drive a - 10ms
Chunk 2 is found off drive b - 5ms
Chunk 3 is found off drive b - 2. 5ms
Chunk 4 is found off drive b - 2. 5ms
Chunk 5 is found off drive b - 2. 5ms
it's not hard to see that, as you increase the number of drives we stripe across, the net seek times will be reduced (obviously to a limitng point). Although I've used a 50% scaling factor here, it is nothing quite like that (and there are diminishing returns as more drives are added due to overhead)Spanning. Windows for instance, has a 26 drive limit (one drive for each letter of the alphabet) ... Now suppose you have, for whatever reason, a requirement for 30 harddrives. This can be done via spanning. What this means is that, at a hardware level, multiple harddrives are grouped/clumped together as a single logical drive (so as far as the OS is concerned, there arent more than 26 drives however the user still has the available capacity of the 30 drives).
Parity. This generically refers to some scheme for creating recovery data. In the event of a data failure, the parity information can be used in conjunction with existing data to reconstruct the 'lost' data.
Mirroring. Drive/data mirroring is just that: data stored on drive a is duplicated on drive b; the difference between mirrorign and a parity configuration is that, in the event of a drive failure, a mirrored setup does not require any "reconstruction" since any data stored on a given drive is also stored on the other drive.
Fault tolerance. Generally expressed in degrees/levels, fault tolerance, in the context of RAID, refers to the number of simultaneous critical drive failures a configuration can sustain without loss of user data. Take mirroring for instance, since any data on drivea is stored on driveb, either drive can fail without loss of data (thus meaning the fault tolerance is 1-drive); should both drives fail, the user will lose their data
Controller. Raid doesn't just "happen" by plugging harddrives into a standard controller however, they require special drive controllers which provide the RAID functionality (naturally this does not refer to software-RAID). The type of RAID available depends on the controller.
Software-RAID. At the OS-level, the OS can 'reroute it's io operations' to simulate a hardwareRAID; such implementations are called software-RAID. The advantage here is that there is no longer a requirement for fancy (and potentially expensive) RAID controllers; the downside is that (a) you cannot 'simulate' all possible RAID levels and (b) performance of a software-RAID will never be able to match a hardware implenmentation.
Sequential vs Random Like the word suggests, sequential refers to accessing data such that the data blocks are arranged sequentially (with repsect to the physical location on the plates) on the disk. Random access refers to non-sequential access.
Hotswap Hotswapping refers to [the ability to] remove a harddrive from a system while the system is still powered up. If you have to power-down before swapping out a HDD then your drive does not support hot-swapping
Matrix/nForce RAID
Intel Matrix RAID -- http://www.intel.com/design/chipsets/matrixstorage_sb.htm
nVidia RAID -- http://www.nvidia.com/object/feature_raid.html
Last edited:
RAID0 - [Pure] Striping
- RAID0 is simply an implementation of parity spread across multiple drives.
- The advantage of RAID0 is that you have improved performance (depending on what you intend to do with the drives) however the downside is that (a) your capacity is that of the smallest drive in the array time the number of drives and (b) there are now two (or more) points of failure for the array (each of the drives can fail, taking down the entire array rendering data on all drives as toast).
- RAID0 is really only benificial when doing sustained (preferably sequential) IO operations. To explicitly say it, you will not see an improvement in random access -- so dont expect any improvement in video game performance.
- To preempt RAID0 fanatics/fanboys, consider this first case,
The above image illustrates the potential for a RAID0 system and is what RAID0 fanatics like to think happens everywhere, all the time. When reality kicks, in the above benchmark is done illustrating maximum sustained throughput. Now when we take the same benchmark and look at office applications,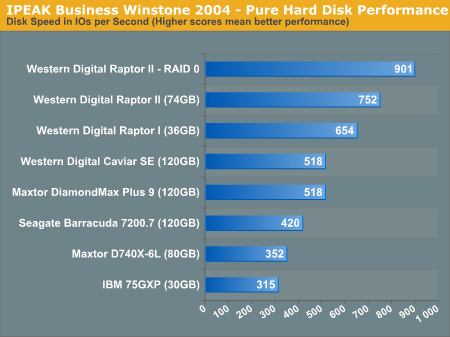
This shows, as expected, that a RAID0 configuration can (and as shown, does) lead to improved performance in office applications. Do note however that the performance advantage is significantly reduced as compared to the maximum/theoretical throughput. Looking at content creation benchmarks (which typically involve larger IO operations and as such, RAID0 benifits should be slightly more observable),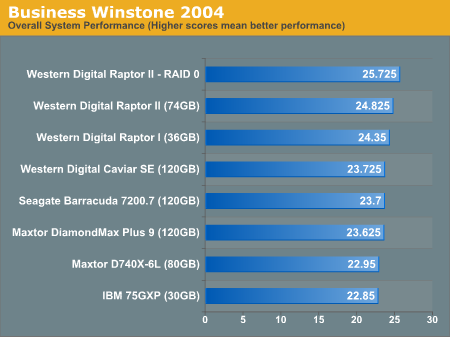
While one cant say that there is a benifit for using RAID0, it is, again, not as significant as the theoretical values. Now let's look at video gaming performance,
It's quite readily apparent that video game performance yields virtually no performance gains. Thus, one can state with a high degree of confidence, short of using applications that involve sustained file transfers (say as a file server that sends and receives CD-sized images or larger) than there will not be any worthwile performance gains. It should be noted however that for scenarios where RAID0 may be useful, there are (a) usually redundancy requirements or (b) better RAID options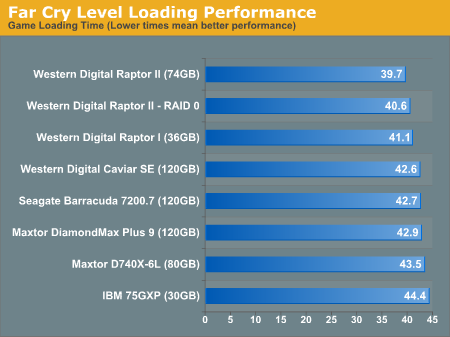
- A minimum of two drives is required
Last edited:
RAID1 - Mirroring
- RAID1 is an implemention of drive mirroring, for every pair of drives (because RAID1 is done in pairs), the contents of DriveA is mirrored in real-time to DriveB
- The advantage of RAID1 is that there is a very solid 1-level of Fault Tolerance (i.e., one drive can completely fail without any loss of data); the downside is that it is not very space efficient (drive capacity of a two-drive pair will be the size of the smaller of the two)
- Since data is stored across both drives, read-performance will be (theoretically) twice that of the individual drive; write performance will be that of the slowest drive.
- A minimum of two drives is required
Last edited by a moderator:
RAID2 - Bitlevel Striping + Hamming ECC
- RAID2 is a 'wierd' RAID level in that, like other RAID levels that implement striping (at a byte level), RAID2 does so at a bit-level. A Hamming ECC (see this for a more indepth look at Hamming ECC) parity is stored across all the drives
- Since parity is generated at the bit-level, any errors detected can be fixed on the fly (byte-level parity cannot do so since there are 8-bits per byte and an even number of errors will go undetected)
- The primary feature of RAID2, the bit-level ECC, is actually what makes RAID2 somewhat useless -- modern harddrives feature this anyways (i.e., you get this feature for free) and as such RAID2 is not used in modern configurations
- The advantage of RAID2 is exceptional read speads since the data is split across very many drives however the downside is that (a) write speed is not so great due to the overhead of dealing with on-the-fly parity generation and validation and (b) numerous drives are required to implement RAID2 making it inefficient
- No commercial implementations exist (or at least viable ones), however drive requirements are very high
RAID3 - Byte-level Striping + Parity
- RAID3 implements classical striping of data (i.e., see the definition of striping above) and partiy is generated and stored on a single drive dedicated for keeping track of the recovery data
- A minimum of three drives is required for implementation (two for the stripe, one for the parity); fault tolerance is a single drive
- Reading performance is excellent and write performance is good (not excellent due to the requirement for parity generation all the time).
- To make things easier to understand, think of RAID3 as RAID0 + Parity
RAID4 - Block-level Striping + Parity
- Very similar to RAID3, RAID4 differs by striping at a block-level (whereas RAID3 works on a bit-level, RAID4 operates on the kilobyte scale). The block size can be adjusted.
- Due to the striping, read performance is exceptional however again, write performance, while good, is limited slightly by the parity generation
- Three drives are required as a minimum for implementation (two for the stripe, one for the parity)
- Has a single-drive fault tolerance
RAID5 - Block-level Striping + Distributed Parity
- Similar to RAID4, RAID5 improves by splitting the parity information across numerous drives in the array (thus removing the write-performance bottleneck)
- Like RAID4, striping is done at a block level (and the stripe size can be adjusted)
- A minimum of three drives is required
- Has a single-drive fault tolerance
- RAID5 offers excellent read performance and good write performance (although improved in comparison to RAID4); should be noted that parity generation can introduce serious system performance degradation issues
RAID6 - Block-level Striping + Double Distributed Parity
- Expands on RAID5 by spanning two parity sets across the array and requires a minimum of four drives for implementation
- RAID6 arrays can sustain two simultaneous drive failures without loss of data
- Read performance is exceptional like RAID5 however write performance is slightly worse [than RAID5] due to the additional write-stream for the second parity set
- Double parity generation requires extensive system resources
RAID7 - Cached Striping + Parity
- RAID7 isnt a confirmed standard and is generally propreitory
- By adding cache to a RAID3/RAID4 configuration, write performance can be significiantly improved
- Generally requires three drives for implementation
- Both read and write performance are usually very good due to the cache
RAID 1+0 (RAID10) RAID 0+1 (RAID01) - Mirroring and Striping
- RAID10/RAID 1+0 is a stripe across a mirror while RAID01/RAID 0+1 is a mirror across a stripe
- Both of these RAID configurations require four drives for implmentation
- RAID10/RAID 1+0 has the same fault tolerance as a RAID1 configuration (i.e., the data is mirrored so not much is required for recovery), RAID 01/RAID 0+1 has the same fault tolerance as RAID5 (single drive failure)
- Both read and write performance is very good
RAID 0+3 (RAID03) and RAID 3+0 (RAID30) - Byte Stripe + Parity + Block Stripe
- Like RAID3, read performance is exceptional (improved due to the increased striping), write performance is also (relatively) improved
- Fault tolerance is a single drive
- A minimum of six drives is required for implementation
RAID 0+5 (RAID05) and RAID 5+0 (RAID50) - Block-Stripe + Distributed Parity + Block Stripe
- Very similar all around to RAID5 and is used often to improve storage capacity
- Fault tolerance is a maximum of three drives
- A minimum of six drives is required for implementation
RAID 1+5 (RAID15) and RAID 5+1 (RAID51) - Mirroring + Block-Stripe + Distributed Parity
- Fault tolerance is potentially five drives
- Read performance is very good, write performance is good due to the parity generation bottleneck
- A minimum of six drives is required for implementation, number of drives must be even
JBOD - Just a Bunch of Drives
- Best comapred to RAID0 as there is no fault tolerance
- Doesnt offer the [potential] performance benifits of RAID0 however it doesnt have the downside of (a) potential complete data loss and (b) drive efficiency is improved (while RAID0 arrays make use of totalSize = numberOfDrives x smallestDrive, a JBOD's maximum size is the sum total of the constituant drives)
- Status
- Not open for further replies.