First of all. You said that I made it sound simple to run a single thread on both sets of pipelines on a module. You said that was something that you cant do with a simple stepping or two. If you were not talking about Zambezi, what is this mysterious unknown processor your talking about? You said you were not talking about Zambezi either? Piledriver hasnt been released yet to make new stepping. Zambezi and Bulldozer is the same processor. So you were talking about Zambezi! I wasnt!
I wasn't talking about Zambezi. I wasn't talking about any processor in particular. By "can't be done in a stepping or two" I simply illustrated that it's not a quick fix, I didn't imply that you said that they should do it for the next stepping. It's like saying it can't be done in a day or two (and then you jumped at me saying that "I never claimed it could be done in exactly two days", which was NOT my point). And since the idea you presented is just not sound AND would require major changes which require major resources too, I merely suggested that they'd be better off improving other things instead of some weird one-thread-two-pipeline-sets fix.
Then you said that a module should get double the performance or it would not be worth it. Then you said that 70-80% was a more realistic figure.
"Nearly double" to be specific. I don't think think it's inappropriate to refer to 70-80% as a realistic figure for most workloads as "nearly double". I didn't mean nearly as in "within several percent". Alright, the choice of word could've been bad, but I simply didn't think of a better word for something that's ~3/4 of something just then. The exact percentage isn't relevant as far as the validity of my point goes (unless it's actually consistently lower than 60%, in which case I'm happy to admit that I was wrong on that account - I simply wouldn't have been aware).
Then you ask 80% of what. AMD claimed that just using around 12% more die space vs. two full cores using a module that it would get around 80% performance of two threads running on a full 2 cores. What do you not get about that?
I do get that. The thing is, though, like I said, your proposed fix is pointless. I'm fairly sure you said that a 10% performance increase would be realistic for this one-thread-two-pipelines fix, which I agree with. But then you'd be using all that extra die space the other core is taking up to run and thread, and the "extra die space" is more than 10%. And it would require a vastly reworked front-end, which would take even more die space and resources. In the end, you'd be making performance increase that can't even be noticed under most circumstances, but even worse performance per silicon, when all that time could've been spent coming up with a better fix. I mean, if you could get ~20% more performance out of an integer core that does not share any components, would it not make more sense to simply drop the other integer core altogether to improve the IPC and make the chip smaller rather than try to force one thread run on both and get a ~10% performance increase?
Then you act like you dont know what I am talking about when I say both set of pipelines on a module because I am not saying integer cores on a module. Which it can be argumentative if you can call them integer cores or not. Which is why I say both sets of pipelines.
No I don't. I simply wasn't sure and asked for clarification. I already made it clear that I posted under the assumption that you were indeed referring to the integer cores.
Then seem confused because I said scheduler instead of OS scheduler.
To be fair, you did say "I said that by running a single thread on a whole module would be a scheduling nightmare when you started hitting above 4 threads because of having to shift threads around on the second set of pipelines" in those exact words. It simply doesn't make any sense in context of OS schedulers. If one module appears as a single hardware thread to the OS (which I assume was the idea behind one thread per module), the OS scheduler simply doesn't play any part in which particular pipeline a thread runs on. I have no idea why you think there's a need to "shift threads around the second set of pipelines". And having more than 4 threads has nothing to do with BD scheduling issues. Even then I don't see how this is relevant. My point, in essence, is that trying to make a single thread run on both pipelines is not sound. That's what I originally said. It doesn't matter whether we're talking about Zambezi or Piledriver (or any realistic x86 CPU), trying to make more than one hardware thread run a single software thread is simply not viable.
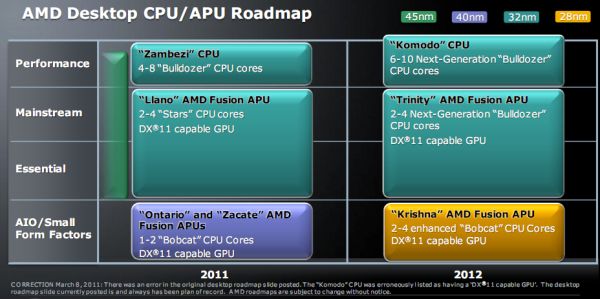
 (although i do think Trinity is supposed to be on piledriver)
(although i do think Trinity is supposed to be on piledriver)